




3年前OpenAI的ChatGPT帶給世人無限驚豔,它使用的超強設備──輝達GPU,成為搶手的超級寵兒,輝達因此躍升全球首家市值5兆美元的冠軍企業。
3年後Google的Gemini 3強勢逆襲, 智力全面封頂,一舉超越ChatGPT,它彎道超車的引擎,竟是自家研發的TPU。
不玩模型的輝達、不賣晶片的Google,原本不在同一個賽道,但卻在競速賽裡擦撞,AI賽局第二回合起跑,會出現什麼變動?
十一月是谷歌(Google)月!
十一月十五日,股神巴菲特創立的波克夏海瑟威公司公布了第三季底持股,外界驚訝地發現,波克夏大幅減持蘋果,並首度海砸四十三億美元(約一千三百億新台幣),買進谷歌母公司Alphabet一七八五萬股,Alphabet一舉躋身波克夏的十大持股行列。
這代表向來鮮少買進科技公司的價值投資者,看好谷歌發展,是對谷歌的雲端發展、AI布局投下信任票;旋即,Alphabet股價一路衝刺,市值一度逼近四兆美元。
接著,十一月二十六日,一份來自摩根士丹利(Morgan Stanley,以下稱大摩)的報告,僅靠著拋出一個「假設」,在華爾街與矽谷引爆燎原大火。
這份報告不再談論谷歌還要向輝達(NVIDIA)採購多少晶片,而是大膽叩問一個可能,「如果谷歌將強大的自研晶片TPU(Tensor Processing Unit,張量處理器)對外販售,不再僅留作自用」,那麼輝達叱吒風雲三年所築起的AI帝國,是否將出現第一道裂痕?
數字會說話,而且震耳欲聾。
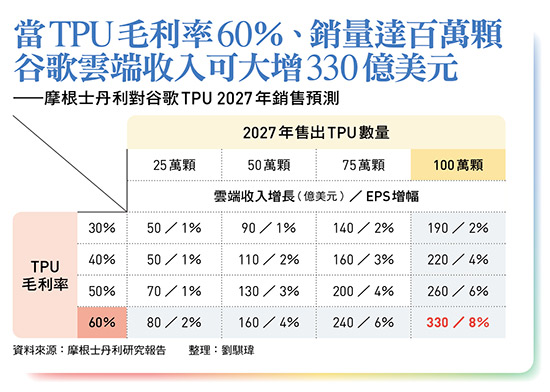
大摩做了一串推算,假設二○二七年谷歌TPU銷售數字從二十五萬、五十萬、七十五萬、一百萬顆,在毛利率分別為三成、四成、五成、六成四種情境下,各種組合對谷歌營收、每股稅後純益(EPS)的貢獻。
大摩假設,當TPU毛利率三○%、銷售二十五萬顆時,可為二七年谷歌雲端營收,增加五十億美元(約一五七○億新台幣),EPS增加一%;如果積極銷售,且TPU毛利率六○%、銷售一百萬顆推估,將灌入高達三三○億美元(約一兆新台幣)營收,EPS增幅達八%。
同時大摩推估,今年谷歌TPU約取得一八○萬顆,若從市場現況推估,比較可能的情境是毛利率五○%,對外賣出五十萬顆,將帶進一三○億美元(約四○八一億新台幣)營收,EPS增加三%。
接著大摩又在五天後(十二月一日)追進,上調谷歌未來三年取得的TPU數量,認為明年可取得三二○萬顆,二七年、二八年更高達五百萬、七百萬顆。推估情境非常樂觀。
這份報告不只是一份財務預測,更像一場市場變局的預言。
兩巨頭「友轉敵」?谷歌從狂買輝達產品 到自研兵器
儘管輝達自己預估,二七年將出貨八百萬顆GPU(圖形處理器),占據市場優勢,但當谷歌這個年砸兩百億美元、狂買輝達產品的超級大客戶,不再僅跟輝達買GPU,同時也豪擲百億美元研發資金,打磨自家兵器時,谷歌與輝達之間究竟是敵是友?
「我們在AI布局上,採取深度差異化的策略,就是擁有全端(Full Stack)技術,」谷歌執行長皮查伊(Sundar Pichai)十月接受英國BBC頻道訪談時表示,全端技術是一種從頭到尾(Soup to Nuts)的完整架構,從底層的晶片、硬體設備建構的物理基礎設施,到創新研究、實操應用,再到將其部署在產品和平台中,包括搜尋、信箱、廣告、YouTube,以及手機作業系統Android等。
皮查伊:這是場賭注。Gemini 3打敗GPT-5.1 阿特曼也汗顏
皮查伊甚至在自家頻道直言,「這個從一六年就開始的全端策略,就是一個賭注,我們大幅提升在基礎設施上的投資,包括資料中心、TPU和GPU等,我們賭要讓谷歌變成一家AI優先的公司。」
作為這場賭注核心的TPU,啟動於一五年,谷歌有鑑於AI發展日行千里,自家建構愈來愈多的資料中心,外購晶片資本龐大、效能又不甚滿意,間接影響研發進展,於是開始悄悄地每年撥數十億美元的預算,轉向自研AI晶片TPU;一六年子公司DeepMind研發的、搭載自家AI晶片機器人AlphaGo,打敗韓國棋士李世乭之際,TPU隨之正式發表。
時至今日,TPU已發展至第七代「Ironwood」,晶片機器學習效能,相較於初代提升三千六百倍,每瓦效能提升約三十倍。
對比與現行AI產業追逐的算力中樞「GPU」,TPU硬體規格乍看與GPU相似,都適合驅動大型AI模型,且都配備高頻寬記憶體以及高速互連技術,但兩位AI明星的關鍵差異,則在於底層的「設計哲學」。
GPU原為繪圖晶片,最早是為了幫助CPU(中央處理器)解析圖像而誕生。假設一個畫面是八百萬像素,它能同時計算八百萬個像素點,各自需要展現的顏色,此平行運算的特性,剛好重合後來的AI模型技術,因此成為AI新時代寵兒;它的強項在於靈活,可以廣泛應用在各種場景。
谷歌的TPU則是典型ASIC(特殊應用積體電路),幾乎是將谷歌演算法「刻」在晶片上,特別是優化了深度學習中頻繁出現的重複運算,這種設計排除多餘功能,專注於讓固定的演算法跑得更快、更穩,如同為單一任務特製的競速機器。
兩者誕生緣起不同,致使它們各具特色。在單晶片極限算力上,輝達GPU仍是霸主,但谷歌TPU憑藉著優異的叢集串聯能力與自研成本優勢,在「單位算力成本」與「每瓦效能」上往往能取得領先。
延伸閱讀:
Google TPU系列2一實測一面倒!Gemini 3完美生成、ChatGPT卻不聽指揮,一圖看谷歌TPU、輝達GPU差異

_20260303095250.jpg_280x210.jpg)


_20260303120013.jpg_280x210.jpg)

